Bring your own DB(BYOD) with respect to D365 and Export to Data-Lake
When you enable the Export to Azure Data Lake add-in, you connect your finance and operations environment to a designated data lake. Authorized users can then copy data from your finance and operations environment to that data lake. Tools such as Power BI and Azure Synapse enable analytics, business intelligence, and machine learning scenarios for data in the data lake.
Data that is stored in the data lake is organized using the Common Data Model. Common Data Model enhances the value of your data in the lake. For example, provides additional metadata in a machine-readable JavaScript Object Notation (JSON) format, so that downstream tools can determine the semantics of the data. The additional metadata includes the table structure, descriptions, and data types.
Export to Azure Data Lake is a fully managed, scalable, and highly available service from Microsoft. It includes built-in disaster recovery.
Here are some of the features that are supported:
- You can select up to 350 tables. All changes to data are continuously updated in the data lake. These changes include insert, update, and delete operations.
- You can select data by using tables or entities. If you use entities, underlying tables are selected by the service.
- You can select both standard and custom entities and tables.
- You can work with data in the data lake by using Microsoft Azure Synapse Analytics or many other third party tools.
How much does this service cost?
Export to Azure Data Lake is an add-on service that is included with your subscription to Dynamics 365 services.
Because Data Lake Storage Gen2 is in your own subscription, you must pay for data storage and input/output (I/O) costs that are incurred when data is read from and written to the data lake. You might also incur I/O costs because finance and operations apps write data to the data lake or update data in it.
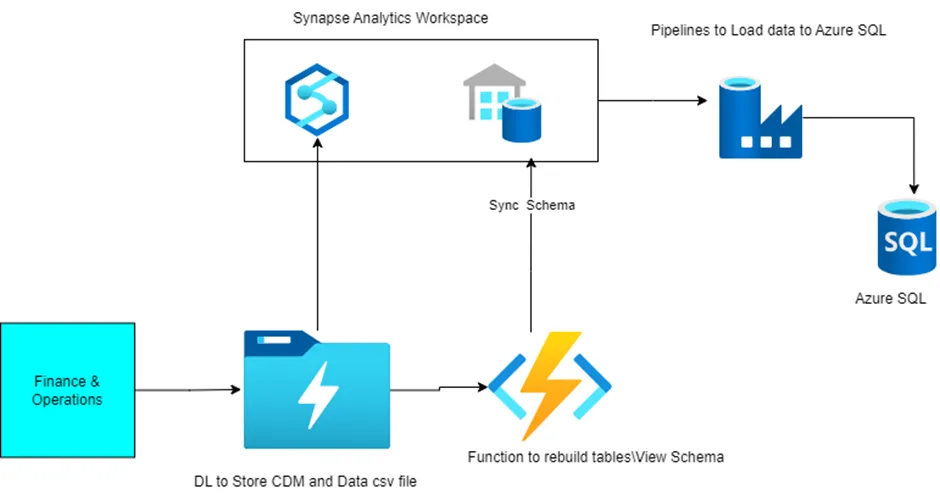
Syncing header-less csv files with your external DB
This is most tricky part of the BYOD as Export to Data-Lake add-in keeps sync D365 backend tables with the csv files.
There are challenges while syncing header-less csv files with the exernal DB:
1 . These csv files don’t have headers and there can be multiple files for the same table if file size exceeds 200mb.
2. Schema Drift- Actually in D365 system, users can add columns to entities and; if any data is added after column addition, the csv file becomes inconsistent in itself as different rows(records) will have the different number of columns. it becomes very tedious task to process the inconsistent csv files.
3. Generally for medium or large organizations, the volume of data is relatively high to process the files by using custom codes.
Solution- I have developed a dynamic, reliable and performant solution to deal with the above scenario.
- Event-driven solution to rebuild the table’s schema in case of schema changes.
- ETL pipelines to process full and incremental load.
Design Diagram: –